Desktop Search Engines
When preparing for exams, I disliked searching manually in PDF, Word and other files. That’s why I started looking for desktop search engines.

Criteria for the tested software were:
- The ability to build an index to allow fast searches.
- At least support for PDF files.
- Preview function.
- Preferably open source.
Docfetcher
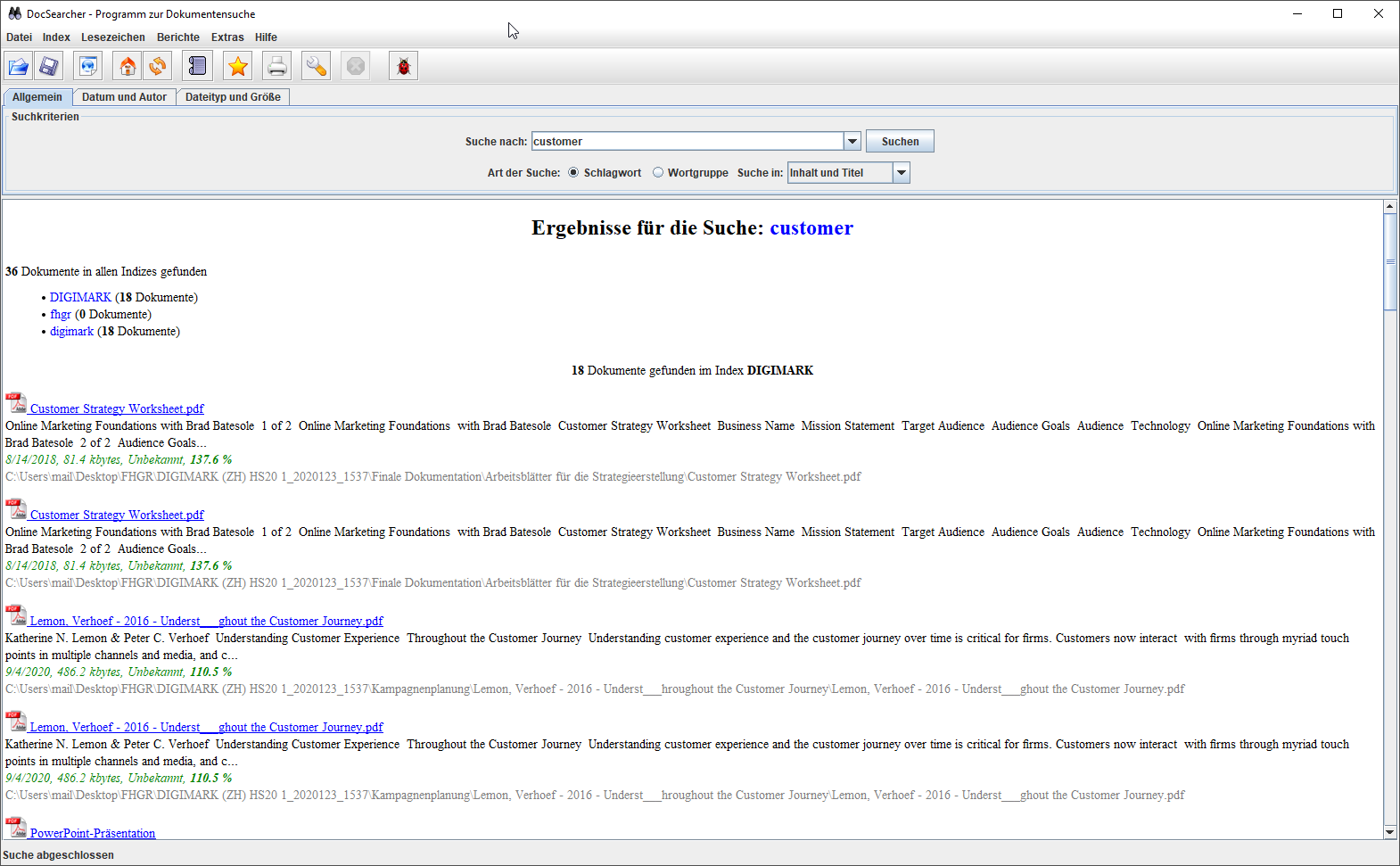
Docfetcher uses Apache Lucene which allows rich syntax search queries, such as wildcards, phrase and fuzzy searches. The user interface is well-arranged, and the preview function works smooth and fast.
Of all the programs tested, Docfetcher is my favorite. Unfortunately, there is a bug since Update 261 in Java 8 which makes the program not executable. A bugfix for the open source software is announced for the beginning of 2021. In addition to the open source version, there is a Pro version with extended functionality.
Pro
- Platform-independent.
- User interface (preview function).
- Complex search queries possible.
Contra
Currently, only executable with older Java version.- Pro version is not open source.
regain
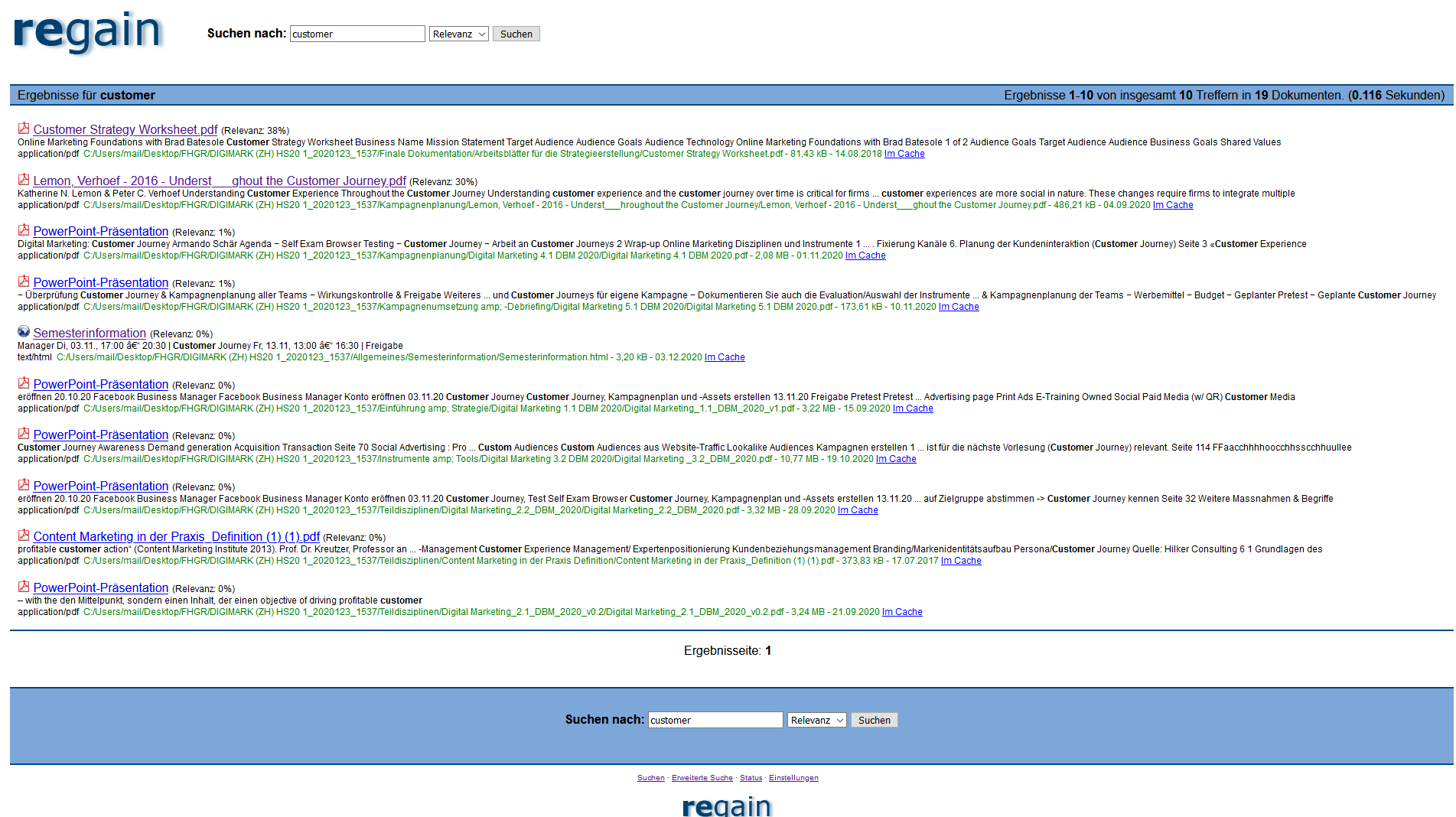
regain is lightweight in its extent. The search engine is powered by Apache Lucene and accordingly allows the use of complex search operators. The search mask is accessed via a browser. The search results appear as a list with a short but not necessarily helpful text preview. However, it is practical that the search results can be opened immediately in the browser, if the format is supported. The search is fast, but you have to search again in the document itself. The project seems to be no longer actively developed. The most recent version dates from 2014.
Pro
- Speed.
- Complex search queries possible.
Contra
- Very rudimentary (no filters, preview not very helpful).
- No further development for quite some time.
Open Semantic Search
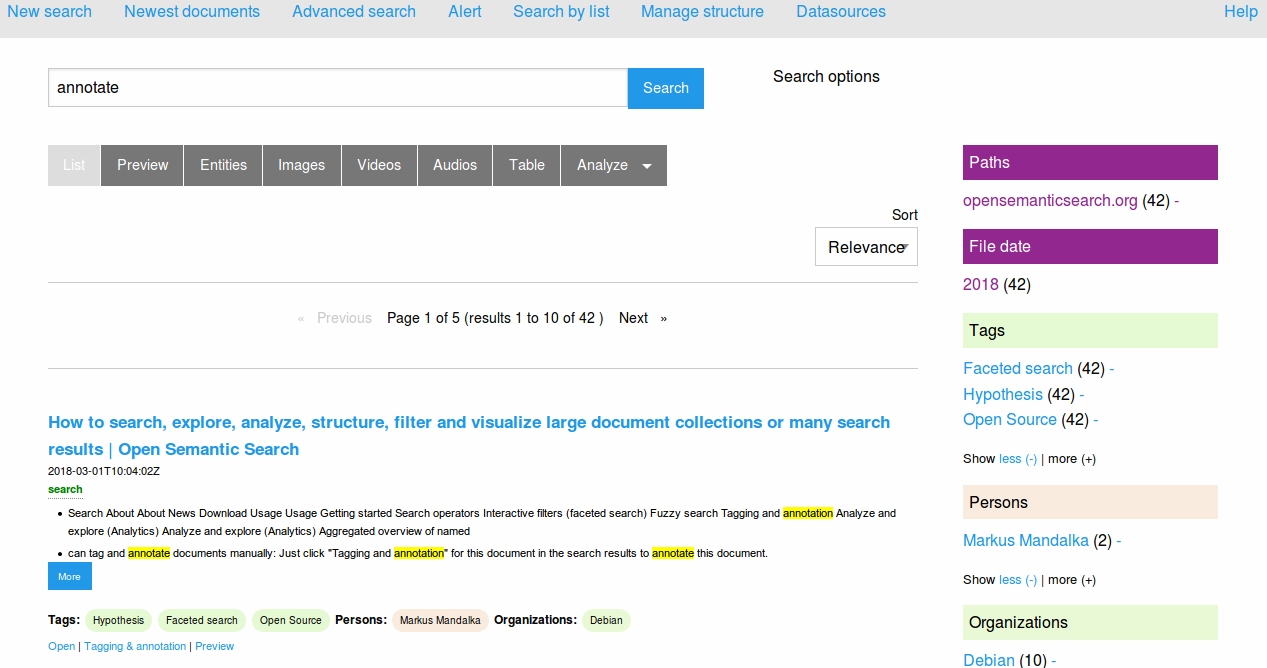
The free search software Open Semantic Search offers a wealth of tools to analyze, organize and search unstructured data. Components are a full text search (incl. search operators, fuzzy search, etc.) or explorative search by document previews in search results and interactive filters. The search environment is based on Apache Solr and Elasticsearch and is offered as a “virtual machine image” which requires a Virtual Box installation. The documentation on the website makes it easy to get started.
Pro
- Platform-independent.
- Preview function for search results (as plain text and embed).
- Complex search queries possible.
- Support for multiple search modes.
Contra
- Dependence on Virtual Box.
- Thus slow and computationally intensive.
DocSearcher
The cross-platform search tool DocSearcher uses Apache Lucene, POI and PDF Box. Searching in numerous text formats is supported. No installation is required, just unpack the downloaded archive and execute the JAR file. The search results are displayed in a list, unfortunately without any preview.
Pro
- Platform independent.
- Complex search queries possible.
Contra
- No preview.
Terrier
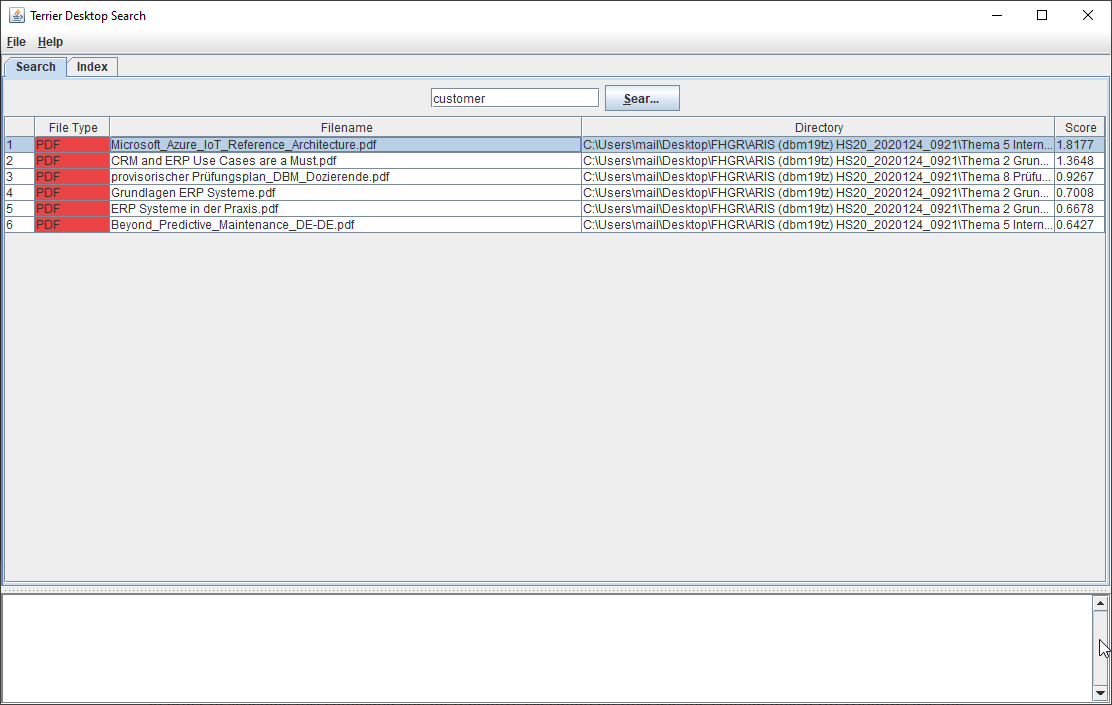
Terrier is an open source search engine which is developed at the University of Glasgow. Terrier is developed using the Java programming language. The feature set is the state of the art in information retrieval. Configuration and indexing mainly done from the commandline. A desktop-demo app and “web-based-terrier” version are available for searching, which are limited in its functionality.
Pro
- State of the art information retrieval.
Contra
- Complex configuration process.
- No UI, demo apps not suitable for productive use.